EGRAs:
Expression Grained Reconfigurable Arrays
Reconfigurable (or field-programmable) arrays are flexible
architectures that can perform execution of applications in a spatial way---much like a
fully-custom integrated circuit---but retain the flexibility of programmable processors by
providing the opportunity of reconfiguration.
The ability to exhibit application-specific features that are not ``set
in stone'' at fabrication time would suggest reconfigurable
architectures as particularly good candidates for being integrated in
customizable processors. Unfortunately, other drawbacks have kept
reconfigurable arrays from becoming a largely adopted solution in that
field. Among different factors, the performance and area gap that still
exists with hardwired logic is certainly one of the most important. The
problem of bridging this gap has been the focus of much research in the
last decades, and important advances have been made. EGRAs provide an
additional step which goes in the direction of decreasing such gap
further.
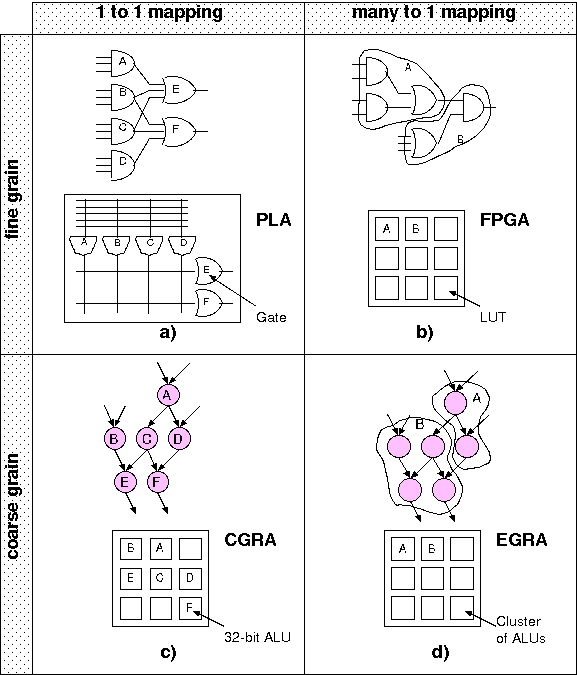
Figure
1: Parallel between the evolution of fine-grained architectures from
simple programmable devices to FPGAs (a and b), and the evolution of
CGRAs from simple cells to the EGRA proposed here (c and d).
A walk through related historical background will help stating this
research's aims and contributions. In the earliest examples of
reconfigurable architecture such as the PLA (Programmable Logic Array),
mapping of ``applications'' (Boolean formulas in sum-of-product form)
is immediate. In fact, each gate in the application is mapped in
a 1-to-1 fashion onto a
single gate of the architecture (Figure 1a).
However, this organization does not scale as applications to be mapped
get more complex. For this reason, CPLDs and FPGAs instead use
elementary components---PLAs themselves, or look up tables---as
building blocks, and glue them with a flexible interconnection
network. Then, programming one cell corresponds to identifying
\emph{more than one gate} in the Boolean function representation
(Figure 1b).
Introducing this additional level is a winning architectural choice in
terms of both area and delay, but such innovations cannot be successful
unless algorithms are available to efficiently map applications to the
new architecture---and indeed efficient algorithms came along to this
purpose, e.g., FlowMap.
An orthogonal step was the introduction of higher granularity cells
(Figure 1c). Fine grain architectures provide high flexibility, but
also high inefficiency if input applications can be expressed at a
level coarser than boolean (e.g. as 32-bit arithmetic operations).
Coarse Grained Reconfigurable Arrays (CGRAs) provide larger elementary
blocks that can implement such applications more efficiently, without
undergoing gate-level mapping.
A variety of CGRA architectures exist but the process of mapping
applications to current CGRAs is usually of the sort: a single node in
the application intermediate representation gets mapped onto a single
cell in the array (again, 1-to-1
mapping). Instead, the architecture we propose in this research (Figure
1d) employs an array cell consisting of a group of ALUs with customizable
capabilities. We consider this the moral equivalent of the switch
from single gates to LUTs that characterizes modern fine grain
reconfigurable architectures. We call this cell RAC
(Reconfigurable Alu Cluster), and the architecture that embeds it EGRA
(Expression Grained Reconfigurable Array).
This allows new and more efficient uses of CGRAs, for example by
enabling implementation of application-specific functional units in a
customizable processor. However, such a change has to be
supported by compilation technology: the proposed architecture would
make little sense without a compilation flow able to map efficiently
onto it. For this reason, this research also explores how a
compiler can aid in the architectural
exploration of the granularity of the cell. See:
Giovanni
Ansaloni, Paolo Bonzini and Laura
Pozzi Design
and Architectural Exploration of Expression-Grained Reconfigurable
Arrays. In
Proceedings of the IEEE Symposium on Application Specific Processors,
Anaheim, Calif, June 2008.